Overview
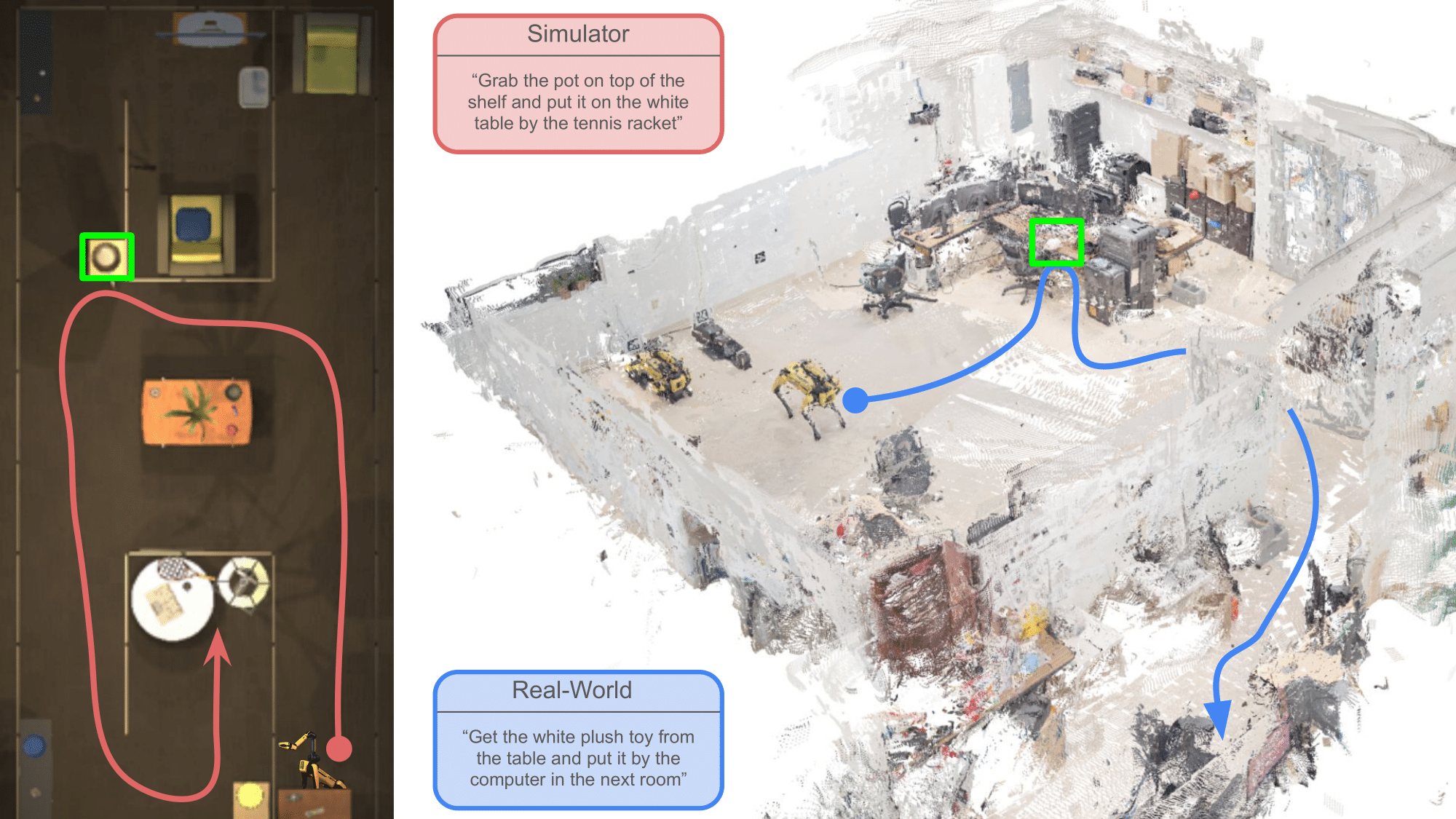
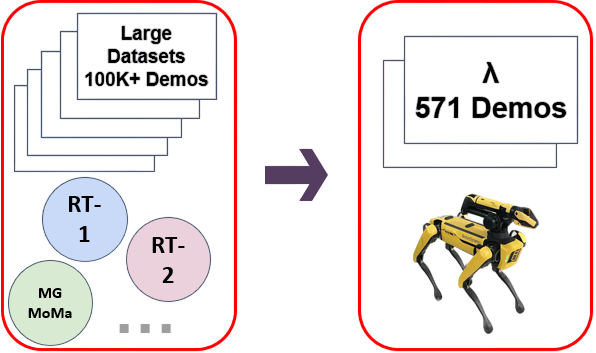
Improving data efficiency for long-horizon mobile manipulation (MoMa) tasks is critical for practical robotic deployment in human environments. Current approaches demand large-scale datasets, which are costly and resource-intensive. To bridge this gap, we introduce the LAMBDA (λ) benchmark, a dataset with 571 language-conditioned, human-collected demonstrations covering diverse indoor multi-room, multi-floor pick-and-place tasks. Unlike existing large datasets, λ emphasizes data efficiency, realistic variability, and replay-verifiability, serving as a valuable testbed for developing robust, practical MoMa models.
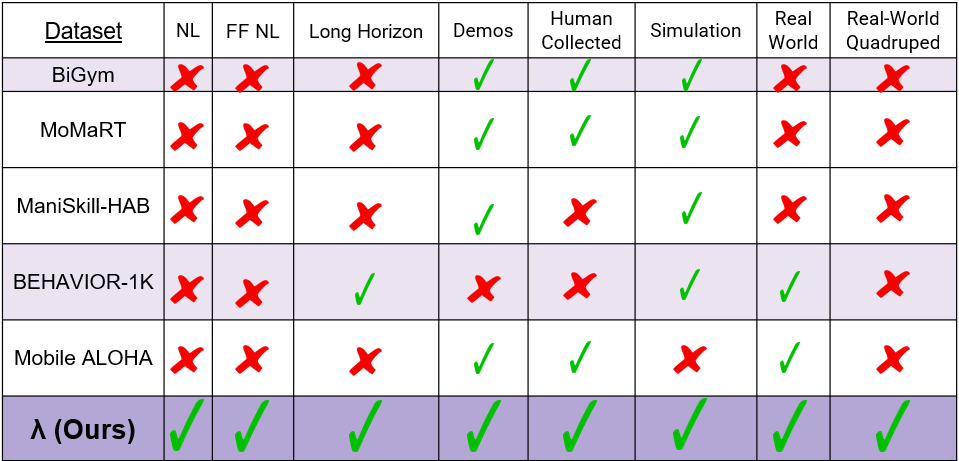
Existing benchmarks for MoMa robotics often lack critical elements necessary for real-world applicability, such as natural language conditioning, long-horizon tasks, human-collected demonstrations, and real-world validation. Most benchmarks either rely on planner-generated data, templated commands, or are restricted to tabletop manipulation, limiting their realism and utility. Very few benchmarks offer free-form natural language instructions, quadruped robot data, or multi-room/floor navigation. The λ benchmark uniquely integrates all these elements, addressing significant gaps and providing a comprehensive evaluation framework for realistic, long-horizon MoMa tasks. (See full table in paper).
Demonstrations

The λ benchmark assesses models' data efficiency specifically for long-horizon mobile manipulation tasks involving language-conditioned, room-to-room, and floor-to-floor pick-and-place activities. It comprises 571 expert human-collected demonstrations, blending simulated data (521 trajectories) with real-world data (50 trajectories), reflecting diverse objects, instructions, and realistic complexity. Tasks are specified via crowdsourced free-form natural language instructions, challenging models to generalize robustly across varied linguistic expressions. The use of both simulated environments and real-world data ensures comprehensive and practical evaluation.
Benchmark's Challenges
1. Data efficiency: Only hundreds of demonstrations -- not hundreds of thousands
2. Long-horizon: Complex MoMa action and observation spaces across rooms and floors
3. Language understanding of free-form instructions, that can be ambiguous, of real-world human needs

Results
To establish baseline performance for λ, we benchmarked two behavior cloning (BC) models: RT-1, a transformer-based MoMa model originally trained on large-scale robot data, and MotionGlot-MoMa, an adapted version of MotionGlot designed for multi-embodiment action generation. Both models were evaluated when trained from scratch and after fine-tuning their pretrained parameters. Additionally, we evaluated LIMP, a zero-shot neuro-symbolic system integrating large multimodal foundation models with task and motion planning, requiring no robot demonstration training. Models were assessed using a success rate metric, where tasks comprise sequential subtasks: navigating to an object, grasping, transporting, and placing it at the goal location, measuring performance comprehensively across long-horizon tasks. Two generalization experiments were conducted: Scene Generalization, testing models on unseen environments with novel layouts and object placements, and Task Generalization, evaluating performance on unseen tasks within known environments.
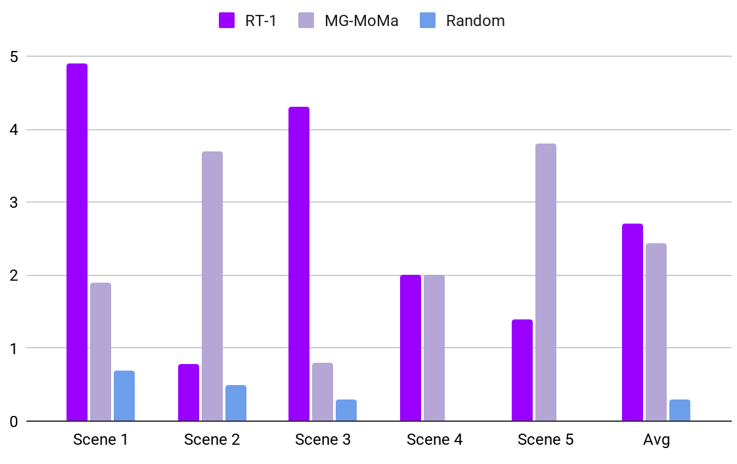
For Scene Generalization, RT-1 and MG-MoMa achieved low success rates averaging 2.7% and 2.4%, respectively, indicating significant challenges in generalizing to unseen environments with novel room layouts and object placements. Both models marginally surpassed a random baseline, confirming minimal learning. Performance varied slightly across scenes based on complexity and spatial constraints, with simpler tasks achieving slightly higher scores. Overall, the results underscore current limitations in end-to-end models for scene generalization in long-horizon MoMa tasks.
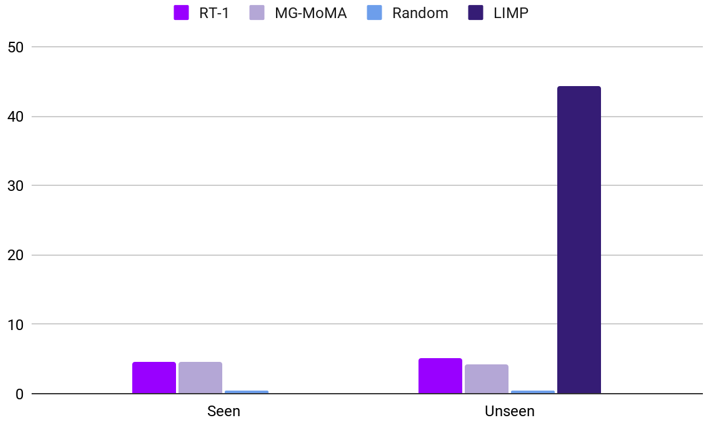
In Task Generalization, RT-1 and MG-MoMa exhibited slightly improved but still low success rates, around 5%. Conversely, LIMP, the zero-shot neuro-symbolic system, significantly outperformed end-to-end models with a 44.4% success rate. This result highlights the promise of neuro-symbolic approaches in generalizing to novel tasks without robot-specific demonstration training.
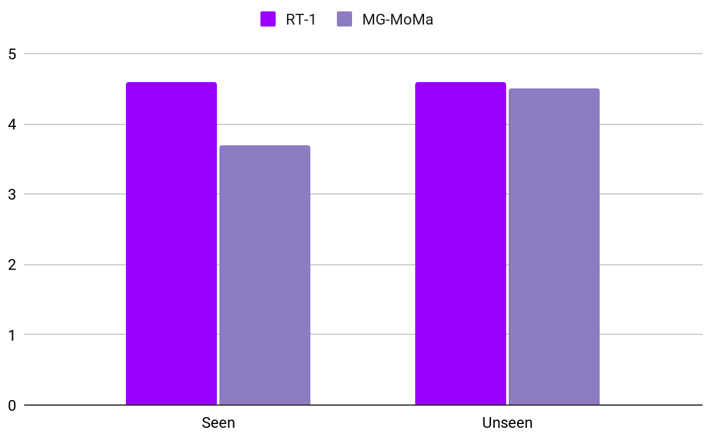
For Task Generalization, we compare results on seen and unseen tasks. While the performance of the baselines is equal for the seen settings, RT-1 outperforms MG-MoMa by 0.9% on the unseen environments. The similar performance also indicates that the models did not overfit.
We also experiment with fine-tuning the pretrained parameters instead of training from scratch, on the Task Generalization experiment. These fine-tuned models did not substantially enhance performance, indicating limited benefits from pretraining on external data. However, MG-MoMa exhibited relatively lower performance on seen tasks compared to unseen tasks when fine-tuned. This may mean that the pretrained parameters biased the models toward their original training tasks and away from effectively adapting to the unique challenges of λ, especially since the original models were trained on real-world data.
Ablations
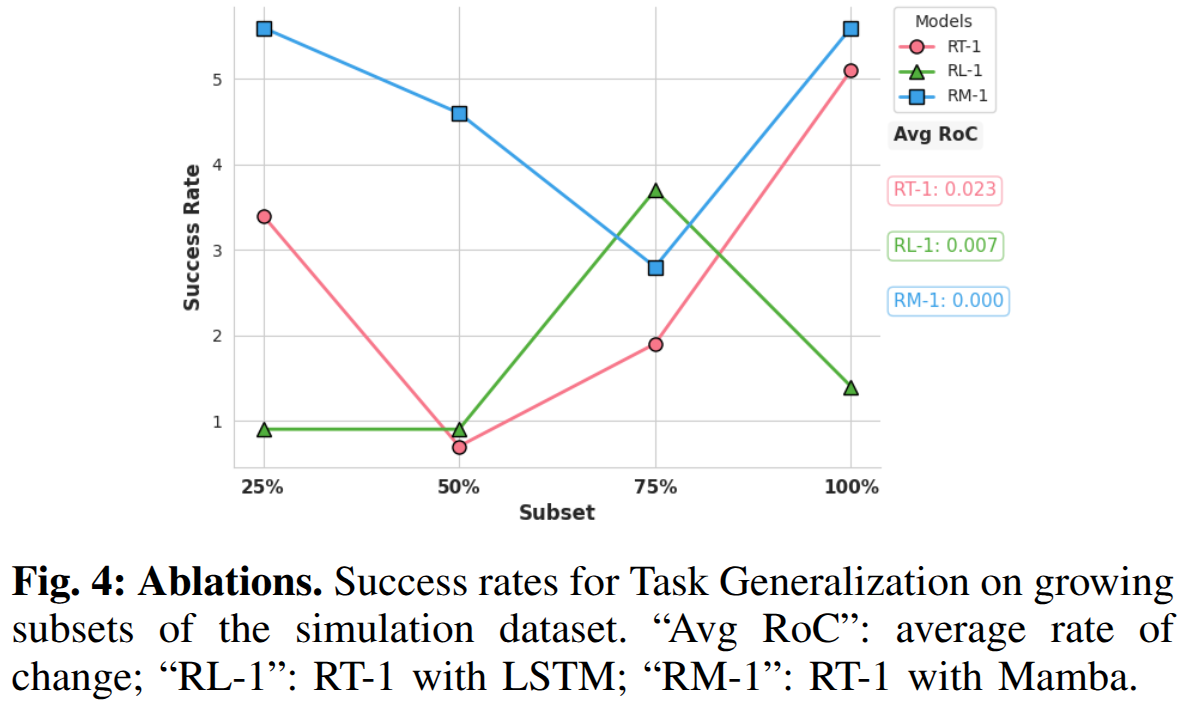
We investigated if data inefficiency played a role in the poor performance. We did that by varying the dataset size. Increasing the dataset size from 25% to 100% led to modest performance improvements for RT-1, indicating data inefficiency.
To investigate the cause of the data inefficiency, we perform architectural comparisons. They revealed that replacing RT-1's transformer with a Mamba architecture (RM-1) resulted in consistently better performance across all dataset sizes, outperforming both the transformer and LSTM alternatives. RM-1's trend (average rate of change) was also constant. These findings suggest that architectural choices influence data efficiency, with the Mamba-based model demonstrating superior generalization capabilities for our long-horizon MoMa tasks.
Acknowledgements
This work is supported by ONR under grant award numbers N00014-22-1-2592 and N00014-23-1-2794, NSF under grant award number CNS-2150184, and with support from Amazon Robotics. We also thank Aryan Singh, George Chemmala, Ziyi Yang, David Paulius, Ivy He, Lakshita Dodeja, Mingxi Jia, Benned Hedegaard, Thao Nguyen, Selena Williams, Tuluhan Akbulut, and George Konidaris for their help in various phases of work.
BibTeX
@misc{lambdabenchmark,
title={{\lambda}: A Benchmark for Data-Efficiency in Long-Horizon Indoor Mobile Manipulation Robotics},
author={Ahmed Jaafar and Shreyas Sundara Raman and Sudarshan Harithas and Yichen Wei and Sofia Juliani and Anneke Wernerfelt and Benedict Quartey and Ifrah Idrees and Jason Xinyu Liu and Stefanie Tellex},
year={2025},
eprint={2412.05313},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2412.05313},
}